Os deseo lo mejor para este nuevo año 2012.
31 dic 2011
Happy New Year / Feliz Año Nuevo
Best wishes for New Year 2012.
Os deseo lo mejor para este nuevo año 2012.
Os deseo lo mejor para este nuevo año 2012.
28 dic 2011
Felices Fiestas / Feliz Navidad

Desearos a todos los lectores de NIR-Quimiometría unas Felices Fiestas, así como un Feliz Año 2012. Como otros años, yo soy uno más de las personas que se desplaza (por carretera) para pasar la Navidad con familiares, así que os quiero felicitar estas fiestas con esta foto tomada a pie de carretera entre Asturias y Madrid.
21 dic 2011
Spectroscopy Europe _T. Davies Column 06 -Dec -2011
Interesting article in Spectroscopy Europe :
Examining diffuse reflection and transmission spectra more thoroughly: Part 1. Instrument noise
by:
Karl H. Norris (Consultant, 11204 Montgomery Road, Beltsville, MD 20702, USA)
with
A.M.C. Davies (Norwich Near Infrared Consultancy, 10 Aspen Way, Cringleford, Norwich NR4 6UA, UK)
The December - 2011 issue of Tony Davies Column, were Karl H. Norris (considered the father of Near Infrared) writes a useful article to look more carefully at the spectra.
How we can use the 4th derivative to study the effect of noise in our data.
Next issue will continue with the second part.
Examining diffuse reflection and transmission spectra more thoroughly: Part 1. Instrument noise
by:
Karl H. Norris (Consultant, 11204 Montgomery Road, Beltsville, MD 20702, USA)
with
A.M.C. Davies (Norwich Near Infrared Consultancy, 10 Aspen Way, Cringleford, Norwich NR4 6UA, UK)
The December - 2011 issue of Tony Davies Column, were Karl H. Norris (considered the father of Near Infrared) writes a useful article to look more carefully at the spectra.
How we can use the 4th derivative to study the effect of noise in our data.
Next issue will continue with the second part.
Olive Paste: Calibration / Validation

I have developed an equation for olive paste, we can see the statistics of the database (number of samples, range, std. dev., mean), also the statistics of the equation, were the most importants are 1-VR and SECV (cross validation statistics), also important the number of PLS factors, and the Math treatments for the model.
This equations for fat and moisture has been added for routine analysis, and validated with a set of new samples of the new campaign 2011.
The validation statistics are:

Calibration performance is quite robust (not bias), and for the fat the Standard Error for Validation (SEP) is lower than the SECV of the calibration. For moisture is a little bit higher, but this is the normal case.
These samples and others, were added to the database and a new calibration developed. New equation statistics are almost similar to the old one. Anyway new variability has ben added of a new campaign and that is allways good.
If we want to improve SEP, we have to study if with some improvements in the sample presentation, replicates,....,improvement in the laboratory error,...,and so on, this statistic becomes lower, and at the same time the calibration stay robust.
19 dic 2011
IRIS Flower Data Set (R-003)
Centramos la matriz con el comando, generando a partir de A una nueva matriz que llamamos "Acentered"
Acentered=scale(A,center=T)
Ahora con la función "eigen":

Acentered=scale(A,center=T)
Ahora con la función "eigen":

Esta es otra forma de proceder con el cálculo de los componentes principales (eigenvectors y eigenvalues), como ya vimos en un post anterior.
17 dic 2011
IRIS Flower Data Set (R-002)
Ver primero: IRIS Flower Data Set (R-001)
See first: IRIS Flower Data Set (R-001)

El comando "summary" nos ayuda a comprender la importancia de cada componente principal:

Los "eigenvalues" son las desviaciones estándar al cuadrado:
Para comprobar la importancia de los eigenvalues, podemos verlos en forma de gráfico:
> lambda<-eigenvalues
> PCs<-c(1,2,3,4)
> plot(PCs,lambda)

save.image("H:\\BLOG\\Curso básico Quimiometria\\IRIS\\parte2.RData")
IRIS Flower Data Set (R-001)
IRIS Flower Data Set


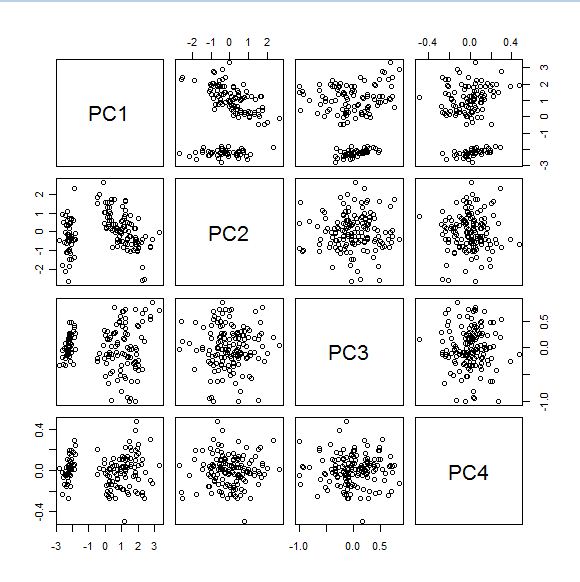
 Representamos los "Mapas de Scores" con la función:
Representamos los "Mapas de Scores" con la función:
pairs(results2$x)
obteniendo:
Tweet
Este es el Link a Wikipedia donde podéis encontrar los datos que utilizó Fisher en su trabajo de 1936. Ya hemos trabajado con estos datos en Excel y los continuaremos usando en nuevas entradas.
En este link, podemos ver las fotos de las flores (IRIS en castellano son lírios).
Represento como LS (longitud del sépalo), AS (anchura del sépalo), LP (longitud del pétalo), AP (anchura del pétalo).
Este es uno de los gráficos de Wikipedia:

Con estos datos ya hemos desarrollado algunos "posts", para familiarizarnos con el uso de matrices en Excel.
Vamos a usar estos mismos datos en fichero CSV e importarlos a "R" para trabajar con ellos, para ello usamos la función: read.table
Se muestran solo los 16 primeros datos por temas de espacio, pues en total son 150 (50 de cada clase). 
Calculamos los componentes principales (centrados):

pairs(results2$x)
obteniendo:
save.image("H:\\BLOG\\Curso básico Quimiometria\\IRIS\\parte1.RData")
16 dic 2011
Diagnostics: Water Vapour bands.

En ocasiones podemos ver en los espectros de ruido, bandas que destacan en la zona de absorción de la humedad (bandas de combinación en torno a 1940 nm y el primer sobretono en torno a 1450 nm), dicho sintoma nos indica que el equipo esta expuesto a una humedad ambiental alta. Es importante tomar medidas para reducir dicha humedad (debida a vapor de agua) y reducir las bandas hasta que sean lo menor posibles o que desaparezcan. Cuando queremos analizar constituyentes con muy baja concentración, la relación señal ruido del equipo debe de ser muy buena, y este tipo de espectros de ruido no contribuye a ello.
Sometimes we can see in the noise spectra, bands that stand in the absorption zone of moisture (combination bands around 1940 nm and the first overtone around 1450 nm), this symptom indicates that the equipment is exposed to a high humidity. It is important to take steps to reduce this moisture and reduce this water vapour bands until they are as small as possible or even disappear. When we analyze constituents with very low concentrations, the Signal to Noise Ratio of the instrument must be good, and this type of noise spectra does not contributes to this.
Tweet
Sometimes we can see in the noise spectra, bands that stand in the absorption zone of moisture (combination bands around 1940 nm and the first overtone around 1450 nm), this symptom indicates that the equipment is exposed to a high humidity. It is important to take steps to reduce this moisture and reduce this water vapour bands until they are as small as possible or even disappear. When we analyze constituents with very low concentrations, the Signal to Noise Ratio of the instrument must be good, and this type of noise spectra does not contributes to this.
13 dic 2011
Postcard from Antequera

Hacía tiempo que no ponía una postal en el Blog. Hoy me he animado a perderme por las calles de Antequera (Malaga) en busca de alguna postal para el blog y esta es la que más me ha gustado, porque transmite la tranquilidad de esta bonita ciudad en esta época del año.
Aprovecho el post para comentar algunas de las aplicaciones para que más se utiliza el NIR (Near Infrared Reflectance) en esta zona de Andalucia.
Por supuesto se trata aplicaciones relacionadas con su fruto más emblemático: "la aceituna". Las almazaras están a pleno rendimiento en esta campaña y el NIR es una herramienta que predice la "humedad" y el "rendimiento graso" a la entrada del fruto (después de ser molida y de preparar una pasta) de una manera rápida y fiable. Se está trabajando también para obtener resultados aceptables para la acidez (en la pasta de aceituna), aunque se trata de un parámetro más complicado.
En el aceite se están analizando por NIT (Near Infrared Transmitance) parámetros como la acidez ( en este caso los resultados son buenos), peróxidos, Ks, humedad, ceras, eritrodiol + uvaol, acidos grasos,.....
Se esta trabajando también para obtener resultados adecuados para algunos de los parámetros importantes de la hoja de olivo (foliares).
Hablando de esta última opción hoy he leído en un artículo de un periódico local el gran potencial de propiedades para la salud (algunas de ellas anticancerígenas) de los extractos de hoja de olivo. Se trata de un estudio de la UCO (Universidad de Córdoba) publicado en la revista Mutation Research.
12 dic 2011
Pairs for the "P" (loadings) matrix
Ver primero: PCA file calculation with "R"
See first: PCA file calculation with "R"
Podemos ver los diferentes planos que forman los PCs entre sí, con la función "Pairs" de "R".
We can see all the combinations of planes (which form the Principal Components) with the function "Pairs" (R).


8 dic 2011
The Power of the Graphics
He visto en varias ocasiones (la última en: Data Mining and Predictive Analytics ) este ejemplo (Anscombe's quartet), que nos sirve para entender la importancia de la visualización de los gráficos. El los cuatro casos las tablas de datos presentan la misma media, desviación estándar tanto para X como para Y, también la correlación X-Y es la misma en los cuatro casos. De modo que unicamente los datos estadísticos no serán suficientes para juzgar estos datos.
Adjunto las imágenes de Wikipedia.
I read not long ago an article in the Tony Davies Column about this (allways look at the plots), and in the last post of one of the blogs I follow (Data Mining and Predictive Analytics ) this matter comes again using this famous example (Anscombe's quartet) to understand the power of the graphics.
In the four figures, we have the same average,standard deviation, correlation,.., for "Y" and "X", so if somebody gives you only the numbers, your idea of how the graphics are can be wrong. You need to ask for the graphics, or to have the original data table to plot them.
I attach also the Wikipedia images.

7 dic 2011
Diagnostics: Warm-up Bias
Después de encendido el equipo (NIR), y encendida la lámpara no se deben de realizar análisis hasta que el equipo este estable. Una de las causas de esta inestabilidad inicial es el Bias, que al comienzo muestra variaciones muy grandes hasta que el equipo se estabiliza en temperatura.
En la imagen podemos ver como el Bias (auto-escala) va disminuyendo en el tiempo (de arriba hacia abajo).
After turning on the computer (NIR), and the lamp,...analysis should not be performed until the instrument is stable. One reason of this initial unstability is the Bias, which at the beginning shows large variations until the instrument is stable in temperature.
In the picture we see how the Bias (auto-scale) decreases over time (from top to bottom).
After turning on the computer (NIR), and the lamp,...analysis should not be performed until the instrument is stable. One reason of this initial unstability is the Bias, which at the beginning shows large variations until the instrument is stable in temperature.
In the picture we see how the Bias (auto-scale) decreases over time (from top to bottom).

En la siguiente imagen, el Bias ya está en la escala adecuada y se ve como se distribuye de manera homogenea por el eje "0" y entre +/- 0,1 mAbs..
The instrument will be stable, once the noise spectra are between + / - 0.100 (mAbs).
In the next image, the bias is already at an appropriate scale (evenly distributed along the axis "0" and between +/- 0,100 mAbs).

Principal Components Analysis with "R" (Part: 001)
This is the first "post" of my new adventure with a software that I consider very interesting and that give to people the oportunity to work with Chemometrics ("R" is free).
To follow these examples, yo can download the following article:
"Multivariate Statistical Analysis using the R package chemometrics"


To follow these examples, yo can download the following article:
"Multivariate Statistical Analysis using the R package chemometrics"

Decidimos seleccionar 5 CP, que explican casi el 80% de las varianza en este ejemplo.
We decided to select 5 PCs, which explain almost the 80% of the variance for this example.

6 dic 2011
Spectra Reconstruction (Excel / R)

Hemos visto estos calculos en muchas de las entrada de este blog.La parte azul esta desarrollada en "R", la negra en "Excel".
We have seen all these calculations in several posts. Blue part is calculated in "R", black part in Excel.
See posts:
5 dic 2011
PCA file calculation with "R".
X es la matriz centrada (X is the centered matrix).
 Podemos comprobar estos resultados con el cálculo del fichero PCA de la entrada anterior.
Podemos comprobar estos resultados con el cálculo del fichero PCA de la entrada anterior.
We can compare this results with the PCA file got in Win ISI in the previous post.
Xcov es la matriz de covarianzas de X (Xcov is the covariance matrix of X).
Con la función "eigen" calculamos los "eigenvectors" y "eigenvalues" de Xcov.(With the function "eigen" we calculate the "eigenvectors" and "eigenvalues" of Xcov).
Para hacer todo al mismo tiempo, podemos usar la función "prcomp".(To do everything at the same time we can use the function "prcomp").
La diferencia es que con eigen obtenemos la varianza y con prcomp las desviaciones estándar.
The diference is that with eigen we get the variances, and with prcomp the standard deviations.

We can compare this results with the PCA file got in Win ISI in the previous post.
3 dic 2011
Distancia de Mahalanobis_review 006
Ejemplo de distancia de Mahalanobis, con solo tres variables con los mismos datos (aportados por la Hoja Excel de Pierre Dardenne en NIRS-Forum) desarrollados en Win ISI.
Mahalanobis Distance practice with only 3 variables (trying to understand the Excel file from Pierre Dardenne in NIRS-Forum)
Datos generados manualmente en Unscrambler, exportados a JCAM-DX e importados posteriormente a Win ISI.
Data generated manually in Unscrambler, exported to JCAM-DX and imported in Win ISI

CERTER.EXE
Se generan:
Fichero PCA

Fichero LIB


Distancias de Mahalanobis al centro de la población
Mahalanobis distance to the mean

To be continued
2 dic 2011
Cross Validation Groups
La selección de número de grupos, así como el número de muestras que pertenecen a cada grupo, tiene cierta importancia a la hora de desarrollar nuestro modelo de calibración. Pongamos por ejemplo el caso de una calibración con 1000 muestras y creamos 2 grupos, por lo que 500 irán a un grupo y las otras 500 al otro. ¿Como lo hace?.
Se pueden seleccionar de una manera aleatoria.
Las pares a un grupo y las impares al otro.
Cuando se crean mas grupos (3 por ejemplo) existen mas combinaciones para poder seleccionarlas:
La 1ª, 4ª, 7ª,......al primer grupo. La 2ª, 5ª, 8ª ,.....al segundo y la 3ª, 6ª, 9ª,..... al tercero
De manera aleatoria.
Cada tercio a un grupo.
....................................
Y no olvidemos la Full Cross Validation (leave one out) en la que hay tantos grupos como muestras.
Debemos de observar las opciones que tiene nuestro software para el desarrollo de la Cross Validation y seleccionar el que nos parezca más adecuado.
También debemos de tener en cuenta en función del que elijamos si ordenamos nuestro conjunto de calibración (en el caso de "leave one out" no tendría importancia) nuestras muestras por valor de constituyente, o por algún otro criterio como podría ser su distancia de Mahalanobis al centro de la población.
Lo recomendable es seguir algún tipo de orden y después seleccionar una selección de tipo sistemática, o seleccionar para los grupos las muestras de una manera aleatoria.
Debemos de tener en cuenta de que en el caso de que una "única muestra" sea muy especial en cierto momento formará parte del conjunto de validación y no habrá ninguna como ella en el de calibración, por lo que será detectada como anómala. Es por tanto conveniente que cuando una muestra esté en el grupo de validación existan muestras similares (en variedad, concentración de analito, procedencia,...,etc) en el conjunto de calibración.
Los estadísticos que obtengamos serán diferentes en función de los grupos, pero si la base de datos es lo suficiente robusta y la validación cruzada está bien estructurada, no debería de haber grandes diferencias.
Manera de selección de las muestras para validación cruzada en Unscrambler:

1 dic 2011
A History of the Sky
Otro interesante vídeo descubierto a través de:
Realmente impresionante este vídeo en el que se muestra una fotograma del cielo, cada 10 segundos, todos los días durante un año en San Francisco. Se trata de una autentica matriz de 20 columnas y18 filas, que hacen los 360 días, pero hay que imaginarla en 3D, con un fondo de (calcular todo un día en segundos y dividirlo por 10.
Cada celda es la secuencia de todo un día.
Cada celda es la secuencia de todo un día.
Por supuesto se ve cuando es de noche, y si os fijáis, se ven los días que ha llovido, el tipo de Luna que podía haber,....,da para mucho juego este vídeo.
Visualizarlo en pantalla completa y con buena resolución.
Podéis visitar el "Post" a que hago referencia, donde da interesantes detalles de como fue realizado.
Lego Robots solving Rubik´s Cube
Descubrí de estos videos a traves de un tweet y de ahí conocí un magnifico blog:
http://blog.revolutionanalytics.com/
Os recomiendo visitarlo.
http://blog.revolutionanalytics.com/
Os recomiendo visitarlo.
Suscribirse a:
Comentarios (Atom)