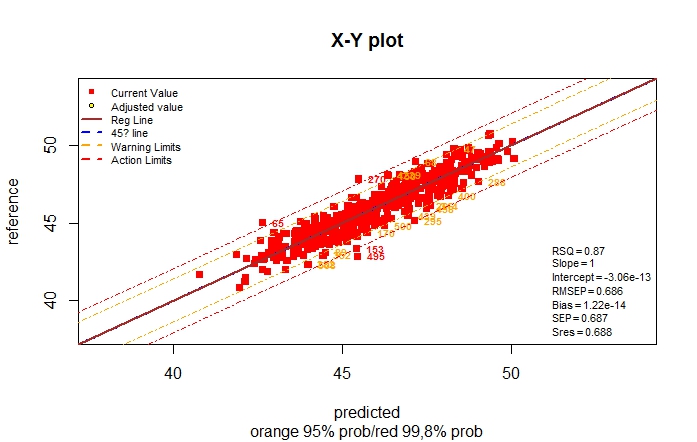
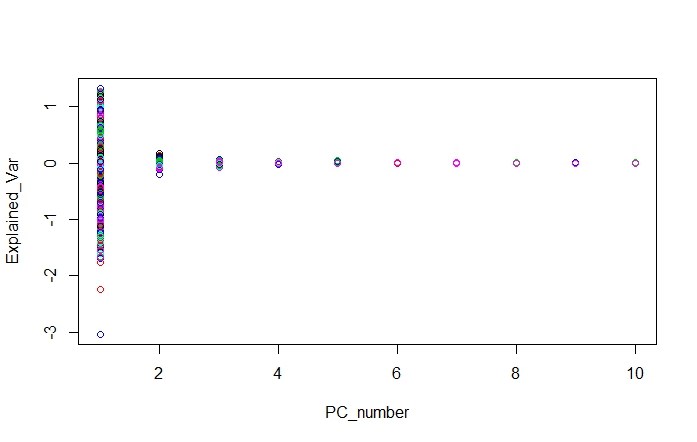
The PLS regression in R, give the values of the loadings. In previous posts we decide to use 4 terms, so we have 4 loadings, one for every term.
See that the first term explain almost all the variability in X, while the rest explain quite few. This does not mean that we don´t need them and they are important.
The first loading looks like an spectrum of a sample, so can be related and affected by the scatter. The others look more similar to the regression coefficients we have seen in the previous post.
So we have lo look to the different loadings shapes carefully.
plot(Prot_plsr,"loadings",comps=1:4,legendpos="top",
lty=c(1,2,4,5),col=c(1,2,4,5),ylim=c(-0.3,0.7))

We can compare individually every loading with the regression coefficients, and we can see how the third and fourth loadings seem to contribute to the regression coefficients.
par(mfrow=c(2,2))
plot(Prot_plsr,"loadings",comps=2,legendpos="top",
plot(Prot_plsr,"loadings",comps=2,legendpos="top",
lty=c(2),col=c(2),ylim=c(-0.3,0.7))
plot(Prot_plsr,"loadings",comps=3,legendpos="top",
plot(Prot_plsr,"loadings",comps=3,legendpos="top",
lty=c(4),col=c(4),ylim=c(-0.3,0.7))
plot(Prot_plsr,"loadings",comps=4,legendpos="top",
plot(Prot_plsr,"loadings",comps=4,legendpos="top",
lty=c(5),col=c(5),ylim=c(-0.3,0.7))
plot(coefficients[,,4],type="l")
plot(coefficients[,,4],type="l")