When we
check a model with a validation set, what we normally look is to the standard
error of prediction (RMSEP) and the RSQ.
After we
check if we have a bias and to the standard error of prediction corrected by
bias. Maybe we are happy with the results if we see that are similar to the
calibration statistics or maybe not so happy and think that the calibration
does not work.
It is
important to check if we have outliers and to remove those samples that could increase
the errors, but if they are not clear outliers, they must stay. What we can do
is if the error is bigger is some parts of the XY plot.
Maybe the calibration
is not so fine for certain range, but it works fine for other range. This way
we can take some conclusion about where to include more samples to improve the
calibration.
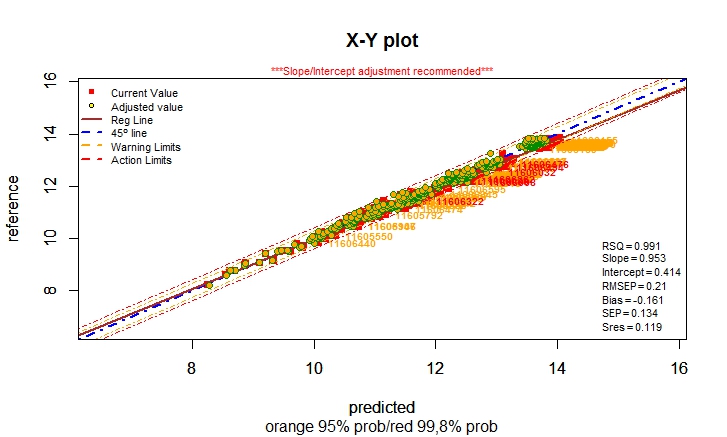
Histograms
will help you with this as well, but also the X-Y plot of reference versus
predicted. In the case of flour there are different types according to the W
parameter.
In the
X-Y plot I can see with an independent validation set that the calibration is
performing well for flour between 200 and 270 of W, with a RMSEP of 9. This tells
me that the calibration is working fine for this type of flour used normally
for pizza products.
The
calibration does not work for soft flour (low W) or hard flour (high W). You
have to decide how to improve it or to separate the flour product into 3
products in order to improve the predictions.
Look
always to the plots and try to find conclusions about the data.